前の10件 | -
インフラエンジニアのためのCassandra情報 ZooKeeperその2 [Cassandra]
ZooKeeperのプログラミングについては、以下のURLに簡単なチュートリアルが
あります。
http://hadoop.apache.org/zookeeper/docs/r3.1.1/zookeeperTutorial.html
今回は、ここに載っているサンプルを使って、カウンターを実現してみます。
ZooKeeperはznodeと呼ばれるツリー構造のデータ構造を持っています。znodeのそれぞれに
対応するオブジェクト(または値)を保存することができます。znodeには、登録、更新時に
一意のバージョン番号が付与されるので、これを使うことで、CAS操作が実現できそうです。
そこで、「/app1/counter」というznodeを作成して、これにカウンター用の数値を代入、参照
するようにします。
カウントアップ時には、CAS操作を行っているので、複数プロセスからの同時書込み時でも値
の一意性が保証されます。
チュートリアルを参考にして、まず「/app1]」の作成部分は、
となり、「/counter」の部分は、
となります。この段階で既に変数として使えるようになっているので、カウンターの
初期値として「0」を入れておきます。
そして、CAS操作を実現するには、バージョン番号を取得し、カウントアップ後に
バージョン番号と一緒にznodeを更新します。このとき他のプロセスが更新していたら
Exceptionが発生するので、はじめからやり直します。
コードは以下のようになります。
出来上がったカウンターのソース(CounterPrimitive.java)は
https://github.com/so-net-developer/Cassandra/blob/master/zookeeper/CounterPrimitive.java
にあります。
使用方法は、以下のとおり。
ZookeeperライブラリをCLASSPATHに指定します。
コンパイル
使い方は、
使用例)
参考までに、rubyでのサンプルも
https://github.com/so-net-developer/Cassandra/blob/master/zookeeper/CounterPrimitive.rb
に載せておきます。rubyに馴染みのひとはこちらのほうが見やすいかも。
あります。
http://hadoop.apache.org/zookeeper/docs/r3.1.1/zookeeperTutorial.html
今回は、ここに載っているサンプルを使って、カウンターを実現してみます。
ZooKeeperはznodeと呼ばれるツリー構造のデータ構造を持っています。znodeのそれぞれに
対応するオブジェクト(または値)を保存することができます。znodeには、登録、更新時に
一意のバージョン番号が付与されるので、これを使うことで、CAS操作が実現できそうです。
そこで、「/app1/counter」というznodeを作成して、これにカウンター用の数値を代入、参照
するようにします。
カウントアップ時には、CAS操作を行っているので、複数プロセスからの同時書込み時でも値
の一意性が保証されます。
チュートリアルを参考にして、まず「/app1]」の作成部分は、
this.root = root_name; ← 「/app1」
counter = counter_name;
// Create ZK node name
if (zk != null) {
try {
Stat s = zk.exists(root, false);
if (s == null) {
zk.create(root, new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
となり、「/counter」の部分は、
b.putInt(0); ← 初期値として0を入れる。
value = b.array();
zk.create(znode, value, Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT); ← znode = /app1/counter
となります。この段階で既に変数として使えるようになっているので、カウンターの
初期値として「0」を入れておきます。
そして、CAS操作を実現するには、バージョン番号を取得し、カウントアップ後に
バージョン番号と一緒にznodeを更新します。このとき他のプロセスが更新していたら
Exceptionが発生するので、はじめからやり直します。
コードは以下のようになります。
int value = 0;
int retry = 0;
do {
try {
Stat stat = zk.exists(znode, false); ←バージョン番号を含むメタデータを取得
byte[] b = zk.getData(znode,false, stat); ←現在の値を取得
ByteBuffer buffer = ByteBuffer.wrap(b);
value = buffer.getInt();
value++; ←カウントアップ
ByteBuffer b1 = ByteBuffer.allocate(6);
b1.putInt(value);
b = b1.array();
zk.setData(znode, b, stat.getVersion()); ←バージョン番号と一緒に、更新した値をセット
retry = 0;
} catch ( KeeperException e) { ←バージョン番号が変わっている場合は、KeeperExceptionが発生する
retry = 1; ←一からやり直し
}
}while(retry > 0);
出来上がったカウンターのソース(CounterPrimitive.java)は
https://github.com/so-net-developer/Cassandra/blob/master/zookeeper/CounterPrimitive.java
にあります。
使用方法は、以下のとおり。
ZookeeperライブラリをCLASSPATHに指定します。
$ export CLASSPATH=./:/usr/lib/zookeeper-3.3.1/zookeeper-3.3.1.jar:/usr/lib/zookeeper-3.3.1/lib/log4j-1.2.15.jarog4j-1.2.15.jar
コンパイル
$ javac CounterPrimitive.java
使い方は、
カウンタの作成: java CounterPrimitive [Zookeeperノードアドレス] n カウンタのインクリメント java CounterPrimitive [Zookeeperノードアドレス] i [増分] カウンタの削除 java CounterPrimitive [Zookeeperノードアドレス] d
使用例)
$ java CounterPrimitive localhost n Input: localhost New Counter $ java CounterPrimitive localhost i 10 Input: localhost Item: 10 $ java CounterPrimitive localhost i 10 Input: localhost Item: 20 <- カウントアップされている。 $ java CounterPrimitive localhost d Input: localhost Deleted
参考までに、rubyでのサンプルも
https://github.com/so-net-developer/Cassandra/blob/master/zookeeper/CounterPrimitive.rb
に載せておきます。rubyに馴染みのひとはこちらのほうが見やすいかも。
インフラエンジニアのためのCassandra情報 ZooKeeperその1 [Cassandra]
CassandraはCASやロックをサポートしていないため、複数のプロセス(またはノード)
から参照して更新されるような一貫性のある共有変数が作れません。
例えばカウンターがその例です。RDBMSであればフィールドをauto incrementにしておけば
複数プロセスからinsertされても常に一意の値が得られます。
Cassandraを使用するアプリケーションでカウンターが必要になったら、そのためだけに
別途MySQL等を使う手もありますが、それではせっかく単一障害点のないCassandraを使って
いても、アプリケーションからするとMySQLのカウンターが単一障害点になってしまいます。
そこで、複数ノードで一貫性と可用性を確保する共有変数領域としてZooKeeperを使ってみます。
ZooKeeperはそれ自体が何かを実行してくれるアプリケーションではなく、分散アプリケーション
を構築するためのサービスとライブラリで構成されています。
このライブラリを使用してアプリケーションを構築することで、ロック、排他制御、同期や
死活監視等いろいろ作ることができます。
サービスはこれら機能を実現するために必要な一貫性と信頼性を持ったデータ領域を提供します。今回は、このデータ領域にカウンターを実装してみます。
ZooKeeperの構造について詳しくは、以下のURLを参照してください。
http://oss.infoscience.co.jp/hadoop/zookeeper/docs/current/zookeeperOver.html
まずは使ってみましょう。
単一ノード(スタンドアロン)でのインストールについては、
http://oss.infoscience.co.jp/hadoop/zookeeper/docs/current/zookeeperStarted.html
を参照すれば簡単に行えますが、複数ノードで動かすことが前提だとちょっと面倒です。
そこで、バイナリ本体、複数ノードで動かす場合の設定サンプル、起動スクリプトを含めた
rpmパッケージを以下に置いておきます。
https://github.com/so-net-developer/Cassandra/tree/master/zookeeper/
ただし、CentOSでしか確認してません。ご利用は自己責任でお願いします。
自分の環境用に作り直したい場合は、SPECファイルも置いておくので、参考までに。
作り方は、Gangliaと同様です。
http://so-net-developer.blog.so-net.ne.jp/hadoop-15-ganglia_1
以降は、このrpmをインストールした環境を前提に説明します。
rpmのインストール。
インストールすると、/usr/lib/zookeeper-3.3.1にバイナリ本体、
/usr/lib/zookeeper-3.3.1/confに設定サンプル、/etc/init.dに起動スクリプトが
コピーされます。
また、ユーザzookeeperが追加されます。
/var/zookeeperが作られ、データ、pidファイル、myidファイルがここに置かれるように
なります。
複数ノードでクラスタ構成に設定します。
クラスタノードを指定(3台の場合)。
zookeeper1,zookeeper2,zookeeper3のところをノードのホストアドレスに変更します。
例)
「server.」の後ろに連番を付けますが、順番には意味はなく各ノードを区別するための番号
となっているようです。
さらにノードを追加する場合は、
と、列を増やしていきます。
ここで定義されたノードのうちのどれかが、ZooKeeperのリーダー役として選出されて、中心的な
役割を果たします。ただし、アプリケーションがこのリーダーを意識することはなく、障害など
ではリーダーが適時切り替わります。
リーダーは、ポート2888を開いて他のノードと通信し、他のノードは3888でお互いに通信を行う。クライアントからの接続は、2181で受け付けます。
zoo.confは全てのノードで同じ内容のものを使用します。起動する前にコピーしておきましょう。次に、さきほど付けたノードの番号をノード自身と結びつけるためのファイル「myid」を
/var/zookeeper以下に作成しておきます。
他のノードでも同様に、2,3,・・・の文字を含むmyidファイルを/var/zookeeper以下に作成して
おきます。
では起動してみましょう。
/etc/init.dに起動スクリプトが登録されているので、起動はサービスとして起動します。
全てのノードで同じように起動します。順番は気にしなくても良いです。
起動確認します。2818番にtelnetして「ruok」とコマンドすると「imok」と返してきます。
次回はカウンターを作ります。
から参照して更新されるような一貫性のある共有変数が作れません。
例えばカウンターがその例です。RDBMSであればフィールドをauto incrementにしておけば
複数プロセスからinsertされても常に一意の値が得られます。
Cassandraを使用するアプリケーションでカウンターが必要になったら、そのためだけに
別途MySQL等を使う手もありますが、それではせっかく単一障害点のないCassandraを使って
いても、アプリケーションからするとMySQLのカウンターが単一障害点になってしまいます。
そこで、複数ノードで一貫性と可用性を確保する共有変数領域としてZooKeeperを使ってみます。
ZooKeeperはそれ自体が何かを実行してくれるアプリケーションではなく、分散アプリケーション
を構築するためのサービスとライブラリで構成されています。
このライブラリを使用してアプリケーションを構築することで、ロック、排他制御、同期や
死活監視等いろいろ作ることができます。
サービスはこれら機能を実現するために必要な一貫性と信頼性を持ったデータ領域を提供します。今回は、このデータ領域にカウンターを実装してみます。
ZooKeeperの構造について詳しくは、以下のURLを参照してください。
http://oss.infoscience.co.jp/hadoop/zookeeper/docs/current/zookeeperOver.html
まずは使ってみましょう。
単一ノード(スタンドアロン)でのインストールについては、
http://oss.infoscience.co.jp/hadoop/zookeeper/docs/current/zookeeperStarted.html
を参照すれば簡単に行えますが、複数ノードで動かすことが前提だとちょっと面倒です。
そこで、バイナリ本体、複数ノードで動かす場合の設定サンプル、起動スクリプトを含めた
rpmパッケージを以下に置いておきます。
https://github.com/so-net-developer/Cassandra/tree/master/zookeeper/
ただし、CentOSでしか確認してません。ご利用は自己責任でお願いします。
自分の環境用に作り直したい場合は、SPECファイルも置いておくので、参考までに。
作り方は、Gangliaと同様です。
http://so-net-developer.blog.so-net.ne.jp/hadoop-15-ganglia_1
以降は、このrpmをインストールした環境を前提に説明します。
rpmのインストール。
$ sudo rpm -ivh zookeeper-3.3.1-0.noarch.rpm
インストールすると、/usr/lib/zookeeper-3.3.1にバイナリ本体、
/usr/lib/zookeeper-3.3.1/confに設定サンプル、/etc/init.dに起動スクリプトが
コピーされます。
また、ユーザzookeeperが追加されます。
/var/zookeeperが作られ、データ、pidファイル、myidファイルがここに置かれるように
なります。
複数ノードでクラスタ構成に設定します。
クラスタノードを指定(3台の場合)。
$ cd /usr/lib/zookeeper-3.3.1/conf $ sudo vi zoo.cfg server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888
zookeeper1,zookeeper2,zookeeper3のところをノードのホストアドレスに変更します。
例)
server.1=xxx.example.com:2888:3888 server.2=yyy.example.com:2888:3888 server.3=zzz.example.com:2888:3888
「server.」の後ろに連番を付けますが、順番には意味はなく各ノードを区別するための番号
となっているようです。
さらにノードを追加する場合は、
server.n=nnn.example.com:2888:3888
と、列を増やしていきます。
ここで定義されたノードのうちのどれかが、ZooKeeperのリーダー役として選出されて、中心的な
役割を果たします。ただし、アプリケーションがこのリーダーを意識することはなく、障害など
ではリーダーが適時切り替わります。
リーダーは、ポート2888を開いて他のノードと通信し、他のノードは3888でお互いに通信を行う。クライアントからの接続は、2181で受け付けます。
zoo.confは全てのノードで同じ内容のものを使用します。起動する前にコピーしておきましょう。次に、さきほど付けたノードの番号をノード自身と結びつけるためのファイル「myid」を
/var/zookeeper以下に作成しておきます。
$ cd /var/zookeeper/ $ echo "1" | sudo tee -a myid
他のノードでも同様に、2,3,・・・の文字を含むmyidファイルを/var/zookeeper以下に作成して
おきます。
では起動してみましょう。
/etc/init.dに起動スクリプトが登録されているので、起動はサービスとして起動します。
$ sudo /sbin/service zookeeper start
全てのノードで同じように起動します。順番は気にしなくても良いです。
起動確認します。2818番にtelnetして「ruok」とコマンドすると「imok」と返してきます。
$ telnet localhost 2181 Escape character is '^]'. ruok imokConnection closed by foreign host. $
次回はカウンターを作ります。
インフラエンジニアのためのCassandra情報 監視その2 [Cassandra]
Nagiosを使ってCassandraのノードを監視してみましょう。
CactiのようにノードのJMXの値を詳細に監視することは出来ませんが、各ノードが
動いているかどうかを確認するだけであれば、ここで紹介する方法が簡単です。
NagiosでCassandraノードの状態を確認するには、やはりJMXを使用します。
Nagiosサーバ側から、Cassandra各ノードのJMXに接続、JMXメトリックスから
「LiveNodes」アトリビュートを取得してノードのアドレスが含まれていれば、ノードは
活性状態であると判断できます。
Cassandraノードである「hogehost」から「LiveNodes」アトリビュートを取得する例:
Nagiosで試すことが出来るサンプルは以下から取得してください。
https://github.com/so-net-developer/Cassandra/tree/master/nagios/
Nagiosの設定は以下のようになります。
/etc/nagios/commands.cfg
/etc/nagios/services.cfg
CactiのようにノードのJMXの値を詳細に監視することは出来ませんが、各ノードが
動いているかどうかを確認するだけであれば、ここで紹介する方法が簡単です。
NagiosでCassandraノードの状態を確認するには、やはりJMXを使用します。
Nagiosサーバ側から、Cassandra各ノードのJMXに接続、JMXメトリックスから
「LiveNodes」アトリビュートを取得してノードのアドレスが含まれていれば、ノードは
活性状態であると判断できます。
Cassandraノードである「hogehost」から「LiveNodes」アトリビュートを取得する例:
String user = "cassandra"; // ノードOSに登録されているユーザ
String pass = "";
String hostname = "hogehost"; // Cassandraノードのアドレス
String JMXURL = "service:jmx:rmi:///jndi/rmi://" + hostname + ":8080/jmxrmi";
Map hm = new HashMap();
hm.put(JMXConnector.CREDENTIALS, new String[]{user, pass});
JMXConnector connector = JMXConnectorFactory.connect(new JMXServiceURL(JMXURL), hm);
MBeanServerConnection connection = connector.getMBeanServerConnection();
ObjectName on = new ObjectName("org.apache.cassandra.service:type=StorageService");
System.out.println(connection.getAttribute(on, "LiveNodes"));
connector.close();
Nagiosで試すことが出来るサンプルは以下から取得してください。
https://github.com/so-net-developer/Cassandra/tree/master/nagios/
Nagiosの設定は以下のようになります。
/etc/nagios/commands.cfg
define command {
command_name check_cassandra_node
command_line $USER1$/check_cassandra_node.sh $HOSTADDRESS$
}
/etc/nagios/services.cfg
define service {
use generic-service
host_name hogehost
service_description cassandra-JMX
contact_groups admins
check_command check_cassandra_node
}
インフラエンジニアのためのHadoop情報 目次 [Hadoop]
インフラエンジニアのためのHadoop情報
・構築編
・運用編
・障害対応
・監視
・その他
・構築編
Hadoopインストール
動かしてみる
クラスタ構築その1
クラスタ構築その2
・運用編
SecondaryNameNode
NameNodeバックアップ
DataNodeの追加
DataNodeの取り外し
ログの切捨て
・障害対応
障害復旧その1
障害復旧その2
障害復旧のために
・監視
状態監視その1
状態監視その2
Gangliaその1
Gangliaその2
・その他
PuppetとHadoop
CDH2のアップデート
インフラエンジニアのためのHadoop情報 ログの切捨て [Hadoop]
Hadoopはlog4jを使って、大量のログを生成しています。連日ジョブを走らせている
ような環境では、NameNodeのログ領域はGバイト単位で肥大化してディスクを圧迫します。
ログの出力ディレクトリをシステム領域と共有している場合などは、ディスク残容量
不足でシステムトラブルの原因にもなりえます。
見落としがちですが、ログの管理もやっておきましょう。
ローテーションについては、Hadoopがやってくれているので、不要なログを抑制して
不要になった古いログは削除するようにします。
ログの抑制についてですが、CDHを使う限りHDFSへのアクセスにパーミッションを設定して
はいないので、HDFSへの監査ログは不要と思われます。
しかも、この監査ログがHDFSへのアクセスの度に記録されるので、肥大化の原因になって
ます。
log4j.properties中に定義されている「SNamesystem Audit logging」をデフォルトの
INFO(全て)からWARNに切り替えます。
以下の行をlog4j.propertiesに追加します。
ちなみに、log4j.propertiesのコメント中には、
の記述がありますが、これを設定してもログに変化は見られませんでした。
次に、古いログを削除しましょう。
例えば、以下のようなスクリプトを/etc/cron.dailyに作成しておき、指定した日にちが
経過したログは削除するようにします。
ような環境では、NameNodeのログ領域はGバイト単位で肥大化してディスクを圧迫します。
ログの出力ディレクトリをシステム領域と共有している場合などは、ディスク残容量
不足でシステムトラブルの原因にもなりえます。
見落としがちですが、ログの管理もやっておきましょう。
ローテーションについては、Hadoopがやってくれているので、不要なログを抑制して
不要になった古いログは削除するようにします。
ログの抑制についてですが、CDHを使う限りHDFSへのアクセスにパーミッションを設定して
はいないので、HDFSへの監査ログは不要と思われます。
しかも、この監査ログがHDFSへのアクセスの度に記録されるので、肥大化の原因になって
ます。
log4j.properties中に定義されている「SNamesystem Audit logging」をデフォルトの
INFO(全て)からWARNに切り替えます。
以下の行をlog4j.propertiesに追加します。
log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=WARN
ちなみに、log4j.propertiesのコメント中には、
#log4j.logger.org.apache.hadoop.fs.FSNamesystem.audit=WARN
の記述がありますが、これを設定してもログに変化は見られませんでした。
次に、古いログを削除しましょう。
例えば、以下のようなスクリプトを/etc/cron.dailyに作成しておき、指定した日にちが
経過したログは削除するようにします。
#!/bin/bash # 15日前のHadoopログを削除する。 CDATE=15 LOGS=/var/log/hadoop-0.20 /bin/rm -r `find $LOGS -ctime +$CDATE`
インフラエンジニアのためのkumofs情報 順序配列 [kumofs]
kumofsで順番を持った集合を作る方法として、前回はリストを紹介しましたが
キー値に規則を作ることで、もうすこし簡単に順番を持つ配列を作ることができます。
まず、CASを使ってカウンターを準備します。
カウンターには予め、値として0を入れておきます。
そして、集合の各要素であるvalueを保存する場合に、並べたい順番にカウンターから
値をひとつづつ受け取りキーを作成し、キーと要素のペアを作っていきます。
キーを作るときは、集合の識別のためのラベルを付けておくと良いでしょう。
例)
「キー値」「要素」
「label0」「value1」
「label1」「value2」
「label2」「value3」
:
「label,100」「value101」
ちょうど、キー値が配列の要素番号の指定にあたり、配列要素の数がカウンターの値に
なるイメージです。
要素を順番に読み出したいときには、ラベルに番号を付けていくだけで出来ます。
リストとは違い、ラベルさえ知っていれば集合中のどの要素にも1回のアクセスで値が
取得できます。
またkumofs本来のアクセス速度をそのまま生かした高速なアクセスが実現できます。
辞書検索のような特定のキー値でのアクセスを維持したまま順番を付けたい場合は
前回紹介したようなリスト形式、キー値にはこだわらず、順番を持った要素に高速に
アクセスしたい場合は順序配列形式というように使い分けをすると良いでしょう。
キー値に規則を作ることで、もうすこし簡単に順番を持つ配列を作ることができます。
まず、CASを使ってカウンターを準備します。
mem.atomic_set('counter') {|val|
val = val.to_i + 1
caunter_val = val
}
カウンターには予め、値として0を入れておきます。
そして、集合の各要素であるvalueを保存する場合に、並べたい順番にカウンターから
値をひとつづつ受け取りキーを作成し、キーと要素のペアを作っていきます。
キーを作るときは、集合の識別のためのラベルを付けておくと良いでしょう。
mem.set('label' << caunter_val.to_s, value, 0, true)
例)
「キー値」「要素」
「label0」「value1」
「label1」「value2」
「label2」「value3」
:
「label,100」「value101」
ちょうど、キー値が配列の要素番号の指定にあたり、配列要素の数がカウンターの値に
なるイメージです。
要素を順番に読み出したいときには、ラベルに番号を付けていくだけで出来ます。
counter = mem.get('counter',true).to_i
for i in 0 .. counter do
value[i] = mem.get('label' << i.to_s,true)
end
リストとは違い、ラベルさえ知っていれば集合中のどの要素にも1回のアクセスで値が
取得できます。
またkumofs本来のアクセス速度をそのまま生かした高速なアクセスが実現できます。
辞書検索のような特定のキー値でのアクセスを維持したまま順番を付けたい場合は
前回紹介したようなリスト形式、キー値にはこだわらず、順番を持った要素に高速に
アクセスしたい場合は順序配列形式というように使い分けをすると良いでしょう。
インフラエンジニアのためのCassandra情報 監視その1 [Cassandra]
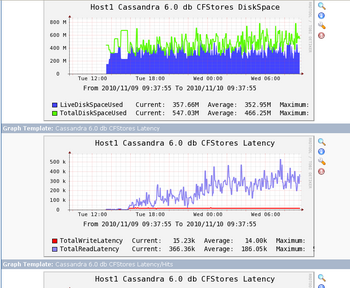
Cassandraの各ノードの状況をモニタリングする方法を検討します。
CassandraはJMXの値を外部から参照できるので、jconsoleを使ってノードの状況を見ることが
できますが、jconsole自体が監視ツールとしては使いにくく、時間的な推移を見ることができ
ないので、各ノードのJMXの値をグラフ化してみます。
グラフ化ツールには、Cactiを使用することにします。
Cactiをインストールします。
Cacti用mysqlデータベースの設定。
Cactiの設定。
起動してGUIから設定継続する。
「http://[Cactiサーバ]/cacti」で初期設定を行う。 GUIの指示どおり、各コマンドへのパスを
設定する。完了するとログイン画面が出る。
このままだと、Cassandraの各ノードをCactiへ登録しても、CPU情報やメモリ量ぐらしかモニタ
できないので、JMXをグラフ化するプラグインを導入する。
使ったのは、こちら。
http://www.jointhegrid.com/cassandra/cassandra-cacti-m6.jsp
Ant1.8を使用するので、バージョンが古い場合はあらかじめインストールしておく。
(Antのバージョンアップが面倒なら、ダウンロードしたAntへパスだけ通しておきましょう)
cassandra-cacti-m6をダウンロード
AntでBuild
jarファイルをCactiディレクトリへコピーする。
cassandra-cacti-m6を展開したソースから、cacti_templatesディレクトリをCactiでインポート
できるようにPC等にコピーしておく。(CentOS上でブラウザ動かせるなら不要)
次からは、CactiのWebUI画面でのGUI設定となります。
CactiのWebUIにadminでログインする。
Console->Import Templateの「参照」ボタンで、「cacti_templates/cassandra-6.0.xml」を
指定する。
オプションはデフォルトのまま、「Import」を実行。
Console->New Graphpsで、「Create New Host」をクリック。
「Description」に名前、「Hostname」にホスト名またはIPを設定、「Host Template」に
「Cassandra 6.0」を選択。「SNMP」は「NONE」にする。その他はデフォルトのまま、
「Create」。
「Associated Graph Templates」にCassandraのチェック項目が表示されているのを確認して、
「Save」。
Console->New Graphpsに戻って、「Host:」プルダウンで、今作ったホスト定義を指定する。
テンプレートチェックボックスにチェックを入れて、「Create」。
入力する内容は以下のとおり。
全て入力したら、「Create」。
Console->Graph Treesで「Add」をクリック。
Nameを「Casssandra」等とクラスタ名を設定。「Create」。
「Tree Items」を「Add」。
「Tree Item Type」プルダウンを「Host」にする。
「Host」に上で作ったホストを選択して、「Create」。
設定が完了したらグラフを表示してみましょう。
WebUI上の、「graphs」タブを開いて、左ペインから上で作成したクラスタ名->ホスト名の順
に選択すると、グラフが表示されます。
デフォルトでのデータ採集までは10分ほどかかるので、それまではグラフの画像が「×」に
なってしまうようですが、しばらくすると表示されるようになりました。
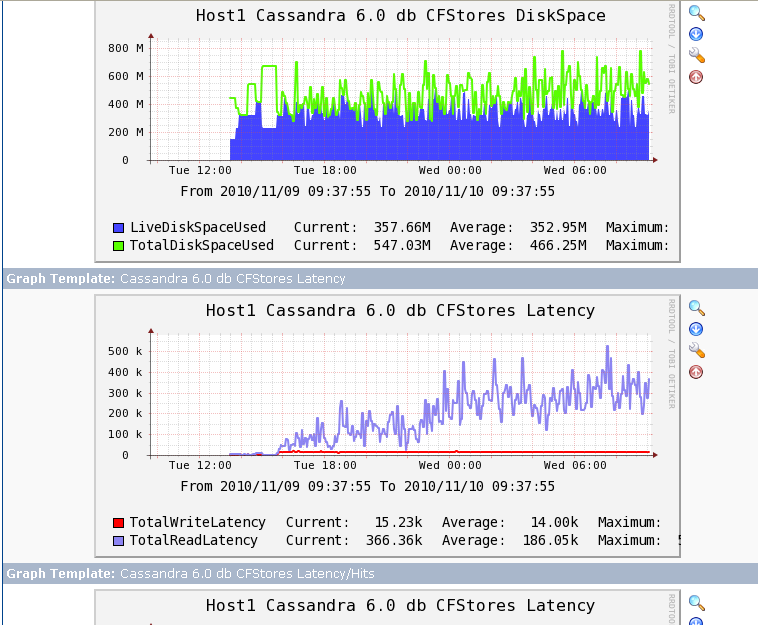
CassandraはJMXの値を外部から参照できるので、jconsoleを使ってノードの状況を見ることが
できますが、jconsole自体が監視ツールとしては使いにくく、時間的な推移を見ることができ
ないので、各ノードのJMXの値をグラフ化してみます。
グラフ化ツールには、Cactiを使用することにします。
Cactiをインストールします。
$ sudo yum install net-snmp $ sudo yum install rrdtool $ sudo yum install mysql $ sudo yum install httpd $ sudo yum install cacti
Cacti用mysqlデータベースの設定。
$ mysql -u root -p Enter password: root mysql> create database cacti; ← Cacti用データベース作成 Query OK, 1 row affected (0.00 sec) mysql> grant all privileges on cacti.* to cactiuser@localhost identified by 'cactiuser'; ← Cacti用データベースアクセスユーザ登録 Query OK, 0 rows affected (0.06 sec) mysql> \q $ mysql -u cactiuser -p cacti < /var/www/cacti/cacti.sql ← Cacti用データベース初期化 Enter password: cactiuser
Cactiの設定。
$ sudo vi /var/www/cacti/include/config.php : $database_type = "mysql"; $database_default = "cacti"; $database_hostname = "localhost"; $database_username = "cactiuser"; $database_password = "cactiuser"; ←このあたり記入 $database_port = "3306"; $ sudo vi /etc/httpd/conf.d/cacti.conf Alias /cacti/ /var/www/cacti/DirectoryIndex index.php Options -Indexes AllowOverride all order deny,allow deny from all allow from 127.0.0.1 allow from 10.0.0.0/255.255.255.0 ←このあたりを修正 AddType application/x-httpd-php .php php_flag magic_quotes_gpc on php_flag track_vars on
起動してGUIから設定継続する。
$ sudo /sbin/service httpd start
「http://[Cactiサーバ]/cacti」で初期設定を行う。 GUIの指示どおり、各コマンドへのパスを
設定する。完了するとログイン画面が出る。
このままだと、Cassandraの各ノードをCactiへ登録しても、CPU情報やメモリ量ぐらしかモニタ
できないので、JMXをグラフ化するプラグインを導入する。
使ったのは、こちら。
http://www.jointhegrid.com/cassandra/cassandra-cacti-m6.jsp
Ant1.8を使用するので、バージョンが古い場合はあらかじめインストールしておく。
(Antのバージョンアップが面倒なら、ダウンロードしたAntへパスだけ通しておきましょう)
cassandra-cacti-m6をダウンロード
$ svn co http://www.jointhegrid.com/svn/cassandra-cacti-m6/ $ cd cassandra-cacti-m6/trunk
AntでBuild
$ ant jar : BUILD SUCCESSFUL Total time: 1 second
jarファイルをCactiディレクトリへコピーする。
$ sudo cp dist/cassandra-cacti-m6.jar /var/www/cacti/scripts/
cassandra-cacti-m6を展開したソースから、cacti_templatesディレクトリをCactiでインポート
できるようにPC等にコピーしておく。(CentOS上でブラウザ動かせるなら不要)
次からは、CactiのWebUI画面でのGUI設定となります。
CactiのWebUIにadminでログインする。
Console->Import Templateの「参照」ボタンで、「cacti_templates/cassandra-6.0.xml」を
指定する。
オプションはデフォルトのまま、「Import」を実行。
Console->New Graphpsで、「Create New Host」をクリック。
「Description」に名前、「Hostname」にホスト名またはIPを設定、「Host Template」に
「Cassandra 6.0」を選択。「SNMP」は「NONE」にする。その他はデフォルトのまま、
「Create」。
「Associated Graph Templates」にCassandraのチェック項目が表示されているのを確認して、
「Save」。
Console->New Graphpsに戻って、「Host:」プルダウンで、今作ったホスト定義を指定する。
テンプレートチェックボックスにチェックを入れて、「Create」。
入力する内容は以下のとおり。
port 8080(JMXのポート) user ホストのログインユーザ(誰でも良い) pass 同パスワード ColumnFamily,Keyspace 運用中のCassandraのそれぞれの値
全て入力したら、「Create」。
Console->Graph Treesで「Add」をクリック。
Nameを「Casssandra」等とクラスタ名を設定。「Create」。
「Tree Items」を「Add」。
「Tree Item Type」プルダウンを「Host」にする。
「Host」に上で作ったホストを選択して、「Create」。
設定が完了したらグラフを表示してみましょう。
WebUI上の、「graphs」タブを開いて、左ペインから上で作成したクラスタ名->ホスト名の順
に選択すると、グラフが表示されます。
デフォルトでのデータ採集までは10分ほどかかるので、それまではグラフの画像が「×」に
なってしまうようですが、しばらくすると表示されるようになりました。
インフラエンジニアのためのCassandra情報 ノードの取り外し [Cassandra]
ノードをクラスタから取り外す場合を考えます。
連続稼動で運用していると、クラスタ全体を止められないので、メンテナンスやハードの入れ替
えを実施したい場合は、ノード1台単位または数台単位で切り離して実施することになるで
しょう。その場合、いきなり稼動中のノードのCassandraサービスを停止したりマシンの電源を
落としてしまうと、クラスタからはそのノードが障害ノードとして扱われてしまいます。
そのように、障害ではなく計画的にノードの取り外しを行いたいときには、decommission処理を
実施します。decommissionすることで、取り外す予定のノードが担当していたデータを他の
ノードへ再配布し、切り離しても問題ないような状態にします。
実行には、nodetoolの動かせるどこかのノードで、
とする。このコマンド発行時に、実際にデータの移動が発生するので、コマンドが完了するまで
しばらく待ちます。
コマンドの実行が終了したら、ノードは取り外せる状態なので、取り外すノードでCassandra
サービスを停止します。
メンテナンスが完了して、ノードをクラスタへ再度参加させる場合は、前回説明したノードの
追加手順を実施します。
ノードを取り外すもう一つのパターンは、障害発生時でしょう。それもすぐ復旧して障害が
取り除けるようなものではなく、ノードの再構築が必要になるような深刻な場合です。
この場合も、復旧までクラスタを障害ノードを抱えた状態のままにはしたくないので、一旦
ノードを取り外してしまいます。
しかし、対象ノードに障害が発生しているので、上で説明したようなdecommisson処理が行えない
のが通例でしょう。(出来たとして)障害ノードのCassandraを停止しても、電源を落としても
クラスタノードからは障害ノードとしての情報が残ったままになります。
そのような場合は、正常稼動中の他のノードから、障害ノードの切り離し処理を実施します。
障害ノードが担当していたデータは、稼動中の他のノードが保持しているレプリカを使って
再配布します。
実行は以下のようにします。
まず、取り外したいノードのtoken値をnodetoolで確認します。もちろん、稼動しているノードで。
Statusが「Down」と表示された欄の、Rangeで示される数値の並びがそれです。
そして、そのtoken値を使って以下のようにします。
なお、ここで指定しているlocalhostは稼動しているノードのことなので間違えないように。
decommisson処理の時と同様、担当範囲のデータの再配布が行われるので、コマンドの実行に
少し時間がかかります。障害のあるノードからデータをコピーしているわけではないので、
完了を待たずに障害ノードは取り外せるでしょう。
完了すると、ringの結果から「Down」だったノード欄が消えて、そこにあったデータ(Loadに
表示されている)が他のノードにコピーされ、どこかのノードの担当データ量が増えているのが
確認できるはずです。
障害が取り除かれて、改めてクラスタに復旧する場合は、前回のように新規ノード追加と
同じ処理を行ってください。(Autobootstrapをお忘れなく)
最後に、ノードの取り外しや復帰を繰り返した結果、ノード間でのデータ量においてアンバランスが
気になってきた場合は、以下のコマンドで手動調整してください。
連続稼動で運用していると、クラスタ全体を止められないので、メンテナンスやハードの入れ替
えを実施したい場合は、ノード1台単位または数台単位で切り離して実施することになるで
しょう。その場合、いきなり稼動中のノードのCassandraサービスを停止したりマシンの電源を
落としてしまうと、クラスタからはそのノードが障害ノードとして扱われてしまいます。
そのように、障害ではなく計画的にノードの取り外しを行いたいときには、decommission処理を
実施します。decommissionすることで、取り外す予定のノードが担当していたデータを他の
ノードへ再配布し、切り離しても問題ないような状態にします。
実行には、nodetoolの動かせるどこかのノードで、
$ ./nodetool -h [取り外す予定のノードアドレス] decommission
とする。このコマンド発行時に、実際にデータの移動が発生するので、コマンドが完了するまで
しばらく待ちます。
コマンドの実行が終了したら、ノードは取り外せる状態なので、取り外すノードでCassandra
サービスを停止します。
メンテナンスが完了して、ノードをクラスタへ再度参加させる場合は、前回説明したノードの
追加手順を実施します。
ノードを取り外すもう一つのパターンは、障害発生時でしょう。それもすぐ復旧して障害が
取り除けるようなものではなく、ノードの再構築が必要になるような深刻な場合です。
この場合も、復旧までクラスタを障害ノードを抱えた状態のままにはしたくないので、一旦
ノードを取り外してしまいます。
しかし、対象ノードに障害が発生しているので、上で説明したようなdecommisson処理が行えない
のが通例でしょう。(出来たとして)障害ノードのCassandraを停止しても、電源を落としても
クラスタノードからは障害ノードとしての情報が残ったままになります。
そのような場合は、正常稼動中の他のノードから、障害ノードの切り離し処理を実施します。
障害ノードが担当していたデータは、稼動中の他のノードが保持しているレプリカを使って
再配布します。
実行は以下のようにします。
まず、取り外したいノードのtoken値をnodetoolで確認します。もちろん、稼動しているノードで。
$ ./nodetool -h localhost ring
Address Status Load Range Ring
145972149051168265451647504111542163748
10.0.0.1 Up 143.15 MB 50557248265472408366546551795111910667 |<--|
10.0.0.2 Down 330.19 MB 145972149051168265451647504111542163748
Statusが「Down」と表示された欄の、Rangeで示される数値の並びがそれです。
そして、そのtoken値を使って以下のようにします。
$ ./nodetool -h localhost removetoken 145972149051168265451647504111542163748
なお、ここで指定しているlocalhostは稼動しているノードのことなので間違えないように。
decommisson処理の時と同様、担当範囲のデータの再配布が行われるので、コマンドの実行に
少し時間がかかります。障害のあるノードからデータをコピーしているわけではないので、
完了を待たずに障害ノードは取り外せるでしょう。
完了すると、ringの結果から「Down」だったノード欄が消えて、そこにあったデータ(Loadに
表示されている)が他のノードにコピーされ、どこかのノードの担当データ量が増えているのが
確認できるはずです。
障害が取り除かれて、改めてクラスタに復旧する場合は、前回のように新規ノード追加と
同じ処理を行ってください。(Autobootstrapをお忘れなく)
最後に、ノードの取り外しや復帰を繰り返した結果、ノード間でのデータ量においてアンバランスが
気になってきた場合は、以下のコマンドで手動調整してください。
$ ./nodetool -h localhost loadbalance
インフラエンジニアのためのCassandra情報 ノードの追加 [Cassandra]
Cassandraのノード取り扱いについて少し取り上げてみます。
Cassandraを複数ノードで起動する方法については、あちこちで既に紹介されているよう
なので、ここでは既に運用中のCassandraクラスタに新規にノードを追加したり、取り外す
場合について書いておきます。
まずは、ノードの追加から。
ノードを追加する場合は、追加するノード側の設定ファイルを書き換えます。動いている
クラスタ側には何もすることがありません。
追加したいノードのstorage-conf.xmlを編集します。
Autobootstrap欄をtrueに変更します。
これをtrueにすると、以下に指定するSeed欄に記入されたアドレスを使って、クラスタへ
参加する処理が開始されます。
ついでに言っておくと、クラスタ中で最初に起動するノードは、他に動いているノードが
無いはずなので、参加処理は必要なく、ここはfalseと指定します。
Seed欄に、クラスタ側で稼動中のノードのどれかのアドレスを指定します。どれでも
かまいません。稼動中の全リストを並べる必要はありません。(並べてもかまいませんが)
ここに記入したアドレスから、クラスタに参加するのに必要な情報をやり取りします。
いったんクラスタに参加してしまうと、情報の受け渡しは、ここに記したアドレス以外の
他のノードから行われるかもしれません。Seed欄に指定したアドレスは参加する時にしか
使いません。なので、一旦参加してしまえば、Seed欄に指定したノードは停止したとして
も問題ありません。(Cassandraの場合は、常に起動しておくノードを想定する必要はない)
Seedは最初わかりにくいのですが、お友達のアドレスを書いておくものと思っておけば
良いでしょう。既に起動中のお友達グループに入りたい場合は、そのグループの誰かを
知っていさえいれば、あとは「お友達のお友達はみなお友達・・・」と自然にグループが作られ
ます。最初に起動するノードについて言えば、「自分」と誰か「他のお友達」のアドレスを書
いておけば、他のノードはグループのお友達誰かを知っていさえすれば良い。
話を元に戻して、
IPアドレスでなくホスト名で書く場合は、そのホスト名で相手に繋がるか確認しておきましょう。
(指定を変更しないかぎり、7000番ポートで待ち受けている)
ThriftAddress欄は、このノードがクライアントアプリケーションからどのように接続される
かで指定が変わります。クライアントから直接接続されることが無いなら、localhostのままで
良いでしょう。また、常にlocalhostから接続されて、アプリケーションでの接続指定も
「localhost」であるならlocalhostのままで良いでしょう。他のノードまたは、クラスタ外の
別ホストから接続される場合は、ノード外から認識できるこのノードのアドレスを
ThriftAddress欄に記入します。
その他のキースペース設定やパラメータ類は、基本的に参加する他のノードに合わせておきます。
設定が終わったら、サービスを起動します。
Seedに指定したノードとの通信が完了したら、数分でクラスタノードから新しいノードが
見えるようになるはずです。(nodetoolのringで確認できる)
Cassandraを複数ノードで起動する方法については、あちこちで既に紹介されているよう
なので、ここでは既に運用中のCassandraクラスタに新規にノードを追加したり、取り外す
場合について書いておきます。
まずは、ノードの追加から。
ノードを追加する場合は、追加するノード側の設定ファイルを書き換えます。動いている
クラスタ側には何もすることがありません。
追加したいノードのstorage-conf.xmlを編集します。
Autobootstrap欄をtrueに変更します。
true
これをtrueにすると、以下に指定するSeed欄に記入されたアドレスを使って、クラスタへ
参加する処理が開始されます。
ついでに言っておくと、クラスタ中で最初に起動するノードは、他に動いているノードが
無いはずなので、参加処理は必要なく、ここはfalseと指定します。
Seed欄に、クラスタ側で稼動中のノードのどれかのアドレスを指定します。どれでも
かまいません。稼動中の全リストを並べる必要はありません。(並べてもかまいませんが)
ここに記入したアドレスから、クラスタに参加するのに必要な情報をやり取りします。
いったんクラスタに参加してしまうと、情報の受け渡しは、ここに記したアドレス以外の
他のノードから行われるかもしれません。Seed欄に指定したアドレスは参加する時にしか
使いません。なので、一旦参加してしまえば、Seed欄に指定したノードは停止したとして
も問題ありません。(Cassandraの場合は、常に起動しておくノードを想定する必要はない)
Seedは最初わかりにくいのですが、お友達のアドレスを書いておくものと思っておけば
良いでしょう。既に起動中のお友達グループに入りたい場合は、そのグループの誰かを
知っていさえいれば、あとは「お友達のお友達はみなお友達・・・」と自然にグループが作られ
ます。最初に起動するノードについて言えば、「自分」と誰か「他のお友達」のアドレスを書
いておけば、他のノードはグループのお友達誰かを知っていさえすれば良い。
話を元に戻して、
10.0.0.1
IPアドレスでなくホスト名で書く場合は、そのホスト名で相手に繋がるか確認しておきましょう。
(指定を変更しないかぎり、7000番ポートで待ち受けている)
ThriftAddress欄は、このノードがクライアントアプリケーションからどのように接続される
かで指定が変わります。クライアントから直接接続されることが無いなら、localhostのままで
良いでしょう。また、常にlocalhostから接続されて、アプリケーションでの接続指定も
「localhost」であるならlocalhostのままで良いでしょう。他のノードまたは、クラスタ外の
別ホストから接続される場合は、ノード外から認識できるこのノードのアドレスを
ThriftAddress欄に記入します。
localhost
その他のキースペース設定やパラメータ類は、基本的に参加する他のノードに合わせておきます。
設定が終わったら、サービスを起動します。
Seedに指定したノードとの通信が完了したら、数分でクラスタノードから新しいノードが
見えるようになるはずです。(nodetoolのringで確認できる)
インフラエンジニアのためのkumofs情報 リスト構造 [kumofs]
kumofsはキーバリューストアの中でも、機能よりもスピード重視なので、それ自体では
キーとバリューペアだけのシンプルな構造しか扱えず、検索やレンジスキャン、キー一覧
の取得などは行えません。
そこで、前回紹介したCAS操作を応用して、kumofsにリスト構造を作ってみます。
プログラマにお馴染みのリスト構造は、「値」と「次の要素を示すポインタ」を持ち
「次の要素」を順番に辿っていくことで、順番を持った値集合を作ることができます。
kumofsを使ってこれを実現するためには、バリュー値に「値、次のキー値」を持たせることで
実現できそうです。
一つのバリュー内に、値と(次の)キーを入れるためには、カンマ区切りにするなどしてデータ
を登録しておきます。
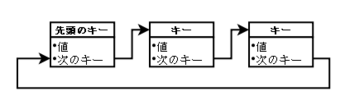
また、操作と構造を簡単にするために循環リストとします。
循環リストは、最後の要素の「次のキー値」が先頭要素の「キー値」になっていて、次の要素を
辿っていくと、先頭に戻ります。ちょうどリングのようなイメージです。
しかしこのままではkumofsで実装するには、面倒なことがおきます。リストに新しい要素を
追加しようとするとき、最後の要素のバリュー内の「次のキー値」を新しい要素のキー値に
置き換える必要があります。ところがkumofsのようなデータストアは複数プロセスから追加
更新が発生することが前提になるので、追加時に「最後の要素」がどこにあるのかを、プロセス
間で共有する仕組みが必要になってきます。
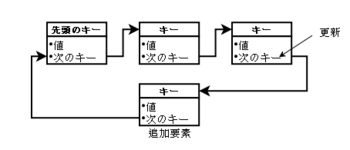
そこで、矢印を逆にしてみます。つまり、「値、前のキー値」をバリューに持たせます。
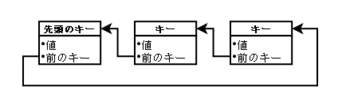
こうすると、要素の追加の時に更新しなければいけないのは、先頭キーのバリューになり、要素
が増えても先頭キーは固定されているので、各プロセスは先頭キーだけ知っていれば要素の
追加ができます。
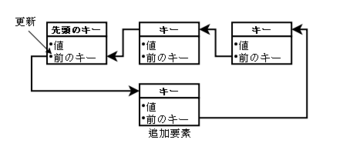
要素追加時の操作は、新しい要素に「値、前のキー値(先頭のキー値のバリュー内にある)」を
登録し、最初のキー値のバリューを「値、新しい要素のキー」に更新します。
複数プロセスから要素の追加が発生する場合を考慮すると、先頭のキー値のバリューを更新する
にはCAS操作が必要になります。そうしないと、他のプロセスで先頭のバリュー値を上書きされて
追加した要素がリングから外れてしまいます。
では、実際に実装してみましょう。
その前に、前回紹介したrubyでのCAS操作を見やすくするため、メソッドを置き換えておきます。
CAS操作は次のようになります。
本題のリスト操作に戻って、要素の追加は
各要素を順に拾っていくには、先頭キーから後ろ向きに辿っていきます。
このようにリスト操作を実装しておけば、先頭要素のキーを知るだけで、集合の要素を
順番に取得することができ、キーや値の一覧も得ることができます。
キーとバリューペアだけのシンプルな構造しか扱えず、検索やレンジスキャン、キー一覧
の取得などは行えません。
そこで、前回紹介したCAS操作を応用して、kumofsにリスト構造を作ってみます。
プログラマにお馴染みのリスト構造は、「値」と「次の要素を示すポインタ」を持ち
「次の要素」を順番に辿っていくことで、順番を持った値集合を作ることができます。
kumofsを使ってこれを実現するためには、バリュー値に「値、次のキー値」を持たせることで
実現できそうです。
一つのバリュー内に、値と(次の)キーを入れるためには、カンマ区切りにするなどしてデータ
を登録しておきます。
また、操作と構造を簡単にするために循環リストとします。
循環リストは、最後の要素の「次のキー値」が先頭要素の「キー値」になっていて、次の要素を
辿っていくと、先頭に戻ります。ちょうどリングのようなイメージです。
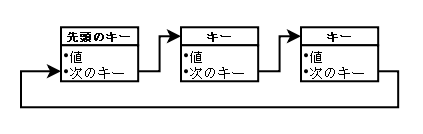
しかしこのままではkumofsで実装するには、面倒なことがおきます。リストに新しい要素を
追加しようとするとき、最後の要素のバリュー内の「次のキー値」を新しい要素のキー値に
置き換える必要があります。ところがkumofsのようなデータストアは複数プロセスから追加
更新が発生することが前提になるので、追加時に「最後の要素」がどこにあるのかを、プロセス
間で共有する仕組みが必要になってきます。
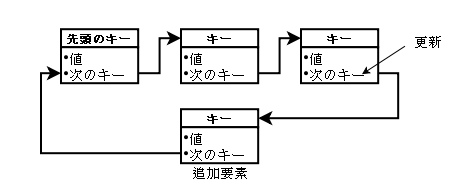
そこで、矢印を逆にしてみます。つまり、「値、前のキー値」をバリューに持たせます。
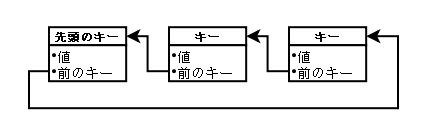
こうすると、要素の追加の時に更新しなければいけないのは、先頭キーのバリューになり、要素
が増えても先頭キーは固定されているので、各プロセスは先頭キーだけ知っていれば要素の
追加ができます。
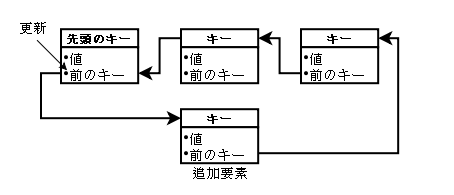
要素追加時の操作は、新しい要素に「値、前のキー値(先頭のキー値のバリュー内にある)」を
登録し、最初のキー値のバリューを「値、新しい要素のキー」に更新します。
複数プロセスから要素の追加が発生する場合を考慮すると、先頭のキー値のバリューを更新する
にはCAS操作が必要になります。そうしないと、他のプロセスで先頭のバリュー値を上書きされて
追加した要素がリングから外れてしまいます。
では、実際に実装してみましょう。
その前に、前回紹介したrubyでのCAS操作を見やすくするため、メソッドを置き換えておきます。
require 'memcache'
class MemCache2 < MemCache
def atomic_set(key)
begin
ret = self.cas(key,0,true){|value| yield(value) }
end until ret == "STORED\r\n"
end
end
CAS操作は次のようになります。
mem = MemCache2.new 'localhost:11211'
mem.atomic_set('key') {|value|
valueに関する操作
}
本題のリスト操作に戻って、要素の追加は
mem.atomic_set('first_key') {|value|
prev_key = value.split(",")[1]
mem.set(new_key, new_value + ',' + prev_key, 0, true)
value = value.split(",")[0] + ',' + new_key
}
各要素を順に拾っていくには、先頭キーから後ろ向きに辿っていきます。
current_key = 'first_key'
while 1
current_value = mem.get(current_key, true)
print "key=#{current_key}, value=#{current_value.split(",")[0]}\n"
current_key = current_value.split(",")[1]
if current_key == 'first_key' then break end
end
このようにリスト操作を実装しておけば、先頭要素のキーを知るだけで、集合の要素を
順番に取得することができ、キーや値の一覧も得ることができます。
前の10件 | -
sd さん

-
nice! 0
記事 34
テーマ パソコン・インターネット
プロフィール
ブログを紹介する


